MetalLB is a software load-balancer for bare metal Kubernetes clusters. In this post we will go through the process by which we deployed MetalLB to our production cluster at BenevolentAI.
The problem
At Benevolent we run a bare-metal Kubernetes cluster for our GPU-based workloads. The production cluster consists of GPU and CPU nodes. In addition to the GPU workloads we have various microservices, databases and data lakes that we need to expose to internal teams. To expose these we deployed NGINX ingress controller (https://github.com/kubernetes/ingress-nginx) as a daemonset across all nodes in the cluster exposed as a NodePort service. Due to the lack of software load-balancer support for bare metal setups in Kubernetes we ran into various network stability issues.
- When resolving hostnames we would get IP addresses of all nodes essentially doing DNS load-balancing
- When a node was down there was a chance an HTTP request will timeout due to DNS load-balancing
- When a node had high load there was a chance an HTTP request will have high latency
- Our DNS entries were massive as they listed all nodes, as such we ran into a few request body limits with our DNS provider
- Adding TCP load-balancers to NGINX ingress was an arduous process of updating a configmap and redeploying NGINX ingress
- Helm templates had “if” statements for cloud and non-cloud environments due to the inability to create LoadBalancer types
The above issues contributed to cluster downtime and instability of workloads since we ran compute intensive workloads. We tried juggling NGINX nodes to non-compute intensive nodes but the other problems with node maintenance kept propping up.
Possible solutions
There are a few solutions out there that solve the above issues. Let’s analyse them and see if they are a good fit for our scenario.
As a first solution we could simply migrate everything to the cloud. The cloud has native support for load-balancers and can pretty much solve all our issues. While these issues can be addressed natively in the cloud, there remain good reasons to use an in-house cluster, particularly for GPU intensive tasks.
A second solution is using Kube-router as a Container Network Interface (CNI). Kube-router (https://github.com/cloudnativelabs/kube-router) can be used as a CNI or as a replacement for kube-proxy among other functionality. It provides the ability to expose your internal clusterIP range to the outside host network so you can simply hit the clusterIP. In our case this required ripping out our current CNI, Calico, and replacing it with kube-router which would mean downtime and rebuilding the cluster from scratch (something that wasn’t that easy to do at that time).
The third solution was MetalLB (https://metallb.universe.tf/), a software load-balancer that we can deploy directly to our cluster in layer2 or BGP mode and it would just work. To leverage the full power of MetalLB we can use BGP and essentially load-balance across all nodes. Our edge router supported BGP, so it was simply a matter of configuring BGP and providing the ASN on MetalLB, resulting in no need to rip out the CNI as MetalLB supports Calico out of the box.
Testing phase
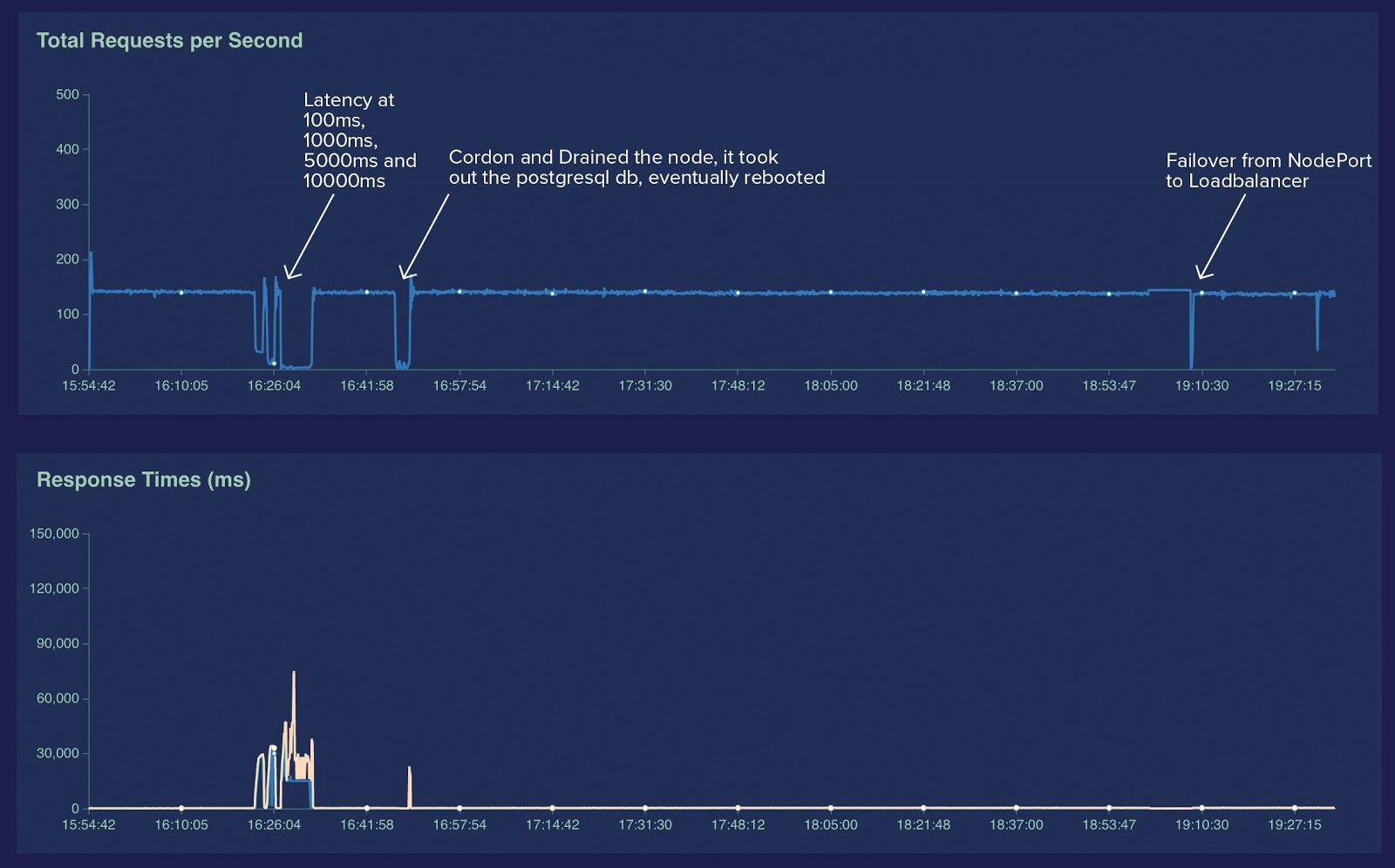
We picked MetalLB as our solution of choice. We carried out testing to make sure there would be no performance penalties. A development Kubernetes environment with 3 nodes was set up with BGP configuration on the edge router, MetalLB, NGINX and external DNS deployed. Two web applications were deployed, one with state and a database and the other stateless roughly simulating our workloads. Their ingresses were exposed on NGINX ingress, and NGINX ingress service was set to a type LoadBalancer with a MetalLB IP. We used locust.io (https://locust.io/) to simulate traffic to the web applications. The goal was to see if taking a node down caused downtime or network instability.
The traffic was simulating 10,000 users in parallel with a pool of 3 nodes. Nodes were taken down one by one, and traffic largely was unaffected except for a few increases in latency as the database was rescheduled. Then artificial latency was created with NetEm on the nodes, and we had an interesting find. MetalLB essentially monitors the Ready status on the node, and when node health status fails MetalLB takes it out of the pool. When a heavily loaded node is falling in and out of Ready status, which is fairly common in our cluster, MetalLB will not help a great deal. But it did resolve the main issues highlighted above. We decided to press ahead and made preparations for the migration day.
Migration day
The migration involved changing the NGINX ingress service to be a load-balancer type and changing from a daemonset to a deployment. We chose a subset of nodes that normally do not have high load in order to avoid the potential latency issues we discovered in the previous section. If this went poorly, the rollback would be fairly non-destructive: we’d simply change back to a daemonset and revert the NGINX ingress service back to NodePort.
Comms were sent out on the usual channels and the SRE team proceeded with all hands on deck. The switch was made and was fairly uneventful. We had to update the static routes exposed on our site-to-site VPN, adding the new MetalLB IP range for our cloud environments to be able to communicate with our private datacenter.
Changes to Deployments and Exposing non-HTTP services
Before MetalLB, if we wanted to expose a non-http service on our cluster, we had to configure a service to be of type NodePort. For our ingress NGINX configuration, a cluster-wide configmap had to be changed each time a new service was introduced and a remaining free port had to be picked.
This configuration was needed for the NGINX ingress so that it could directly route traffic on that port to the correct underlying service. This also meant that a lot of services could not run on their native ports. Additionally, the hostname for all the services was the same but on a different port. This meant that if even if we wanted to have database in our private DC cluster running on port 1234 and another database in our EKS cluster running on port 5678, we would end up in a situation where users could connect to the EKS cluster database on port 1234 and end up talking to the on-prem database. This is obviously not ideal.
Enter MetalLB. For non-HTTP services, we can now simply set the type of the service to LoadBalancer. In addition, if we want to expose the service on a hostname we can now do this by adding a service annotation. This means that each hostname is now tightly coupled to a service. Finally, there’s no cluster-wide configuration to be maintained and we no longer require HTTP-only ingress.
For HTTP services, the change to MetalLB was completely transparent. All ingress configurations continued to keep working as expected.
Conclusion
MetalLB has provided stability, uniformity and reliability to our bare metal Kubernetes cluster. We would like to thank the MetalLB contributors on Github (https://github.com/MetalLB/MetalLB/graphs/contributors) for their extensive documentation and building such a powerful tool. Ever since we deployed MetalLB, network stability issues have been reduced by roughly 80% and Benevolent can continue to focus on accelerating drug discovery through AI.
Back to blog post and videos